Textexture is outdated and is not supported any longer. Our new text visualization tool InfraNodus supports English, Russian, German, French and has advanced import, export, sharing, and filtering features:
www.infranodus.com
Open this page from your iPad or iPhone.
Click the action button (Square with Arrow on it) on your iPad / iPhone and choose "Add Bookmark".
Edit the Title of the bookmark to say "Textexture" (or whatever you like).
Save the bookmark
Copy the code below. (Hold your finger down on it until the copy paste handles pop up, then select it all and copy it).
Choose the "Textexture" bookmark you just created.
Click on the URL and delete it.
Paste the code you copied in the earlier step (tap and hold your finger in the empty field until the Paste option appears).
Return to the bookmarks, tap "Done" and you're finished.
To use it, when you're on the page or youtube video you'd like to visualize as a network, open the Bookmarks folder (tap the book symbol) and tap the "Textexture" bookmark. You'll be able to edit any notes and save the link straight into Delicious.
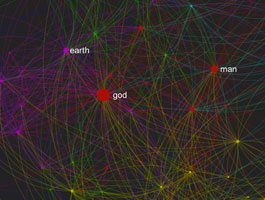
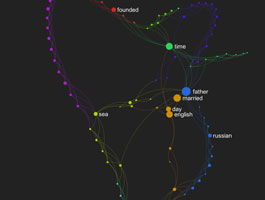
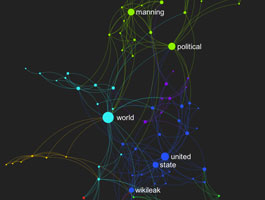
This is a graph of your text "Textextroduction". The colors designate distinct communities of words within this text that appear more often next to each other (clusters of meaning circulation). The bigger the node, the more different clusters of meaning it connects.
MOVE → click on the black space and drag
ZOOM → scroll or swipe over the trackpad
WORD'S CLUSTER → hover the cursor over the word node